A l’occasion de la semaine du libre accès (open access week, du 21/25 octobre 2013), j’ai découvert un peu plus le projet MyScienceWork (MSW) qui se veut être un projet de réseau social centré sur les sciences. Ces réseaux ne sont pas nouveaux, ils sont assez nombreux : de Researchgate.org à Academia.edu. De façon plus claire, sur la première page de son site web, MSW propose un moteur de recherche assez large et qui affiche au compteur 28 millions de publications, … Certains chercheurs me diront que c’est spectaculaire, merveilleux et qu’il y a tout dans ces moteurs de recherche de réseaux sociaux mais je répondrai qu’il est facile d’afficher 28 millions de publications : il suffit de moissonner soit le web et de trier les sources, soit des entrepôts d’archives ouvertes selon le protocole OAI-PMH et de faire comme OAIster.org il y a quelques années : grossir, grossir, grossir… Ensuite il faut bien sur une interface et des filtres (facettes, etc.). Il est facile de faire du chiffre dans ce domaine là quand l’OAI-PMH permet le moissonnage gratuit de métadonnées et la récupération – par exemple – des articles en PDF qui y sont déposés. Testant le moteur de recherche de MSW justement, quelle ne fut ma « surprise » de voir que ce réseau – tout en se réclamant de libre accès (leur slogan est « MyScienceWork: Frontrunner in Open Access » – en malmène largement les principes ; voir construit son projet en privatisant de la connaissance en libre accès.
Comme beaucoup de personnes, à la vue d’un outil de recherche en ligne, mon narcissisme reprend du poil de la bête, je requête MSW sur mon patronyme : un grand nombre de mes articles, pré-publications, documents sortent. Je me dis alors qu’ils moissonnent HAL-SHS, l’archive ouverte nationale, et que dont voilà une belle initiative valorisant les contenus en libre accès. Hélas, voulant accéder au document PDF de l’un de mes papiers (en libre accès), je découvre qu’il faut avoir un compte MSW pour télécharger le document ou le lire en ligne (c’est à dire utiliser le lecteur PDF de MSW). Résumons, alors que mes articles sont libre accès dans HAL-SHS et au passage que je me suis battu (avec les éditeurs) pour qu’ils le soient, MSW demande aux utilisateurs venant sur leur moteur de recherche de se créer un compte pour voir mes papiers ! Sans compte dans MSW impossible de télécharger l’article PDF ou de le lire.
Pire, il n’est même pas signalé l’origine des publications : ni source, ni référence d’éditeurs, et donc HAL-SHS n’est même pas mentionné ! L’url pérenne fournie par HAL-SHS n’est pas indiquée non plus, le lien proposé pointe sur une adresse « maison » de MSW qui n’a rien de pérenne (elle est explicite, mentionne le nom du réseau : http://www.mysciencework.com/publication/show/1107184/les-moteurs-de-recherche-profitent-aussi-de-la-semantique). Bref, on ne sait pas d’où vient l’article, ni dans quoi il a été publié ! Parfois une mention « In » apparait, mais pas dans mes articles. Voir la différence de traitement du même papier que j’ai déposé dans HAL-SHS et moissonné dans MSW (éditeur mentionné par ex. dans mon dépot HAL-SHS) :

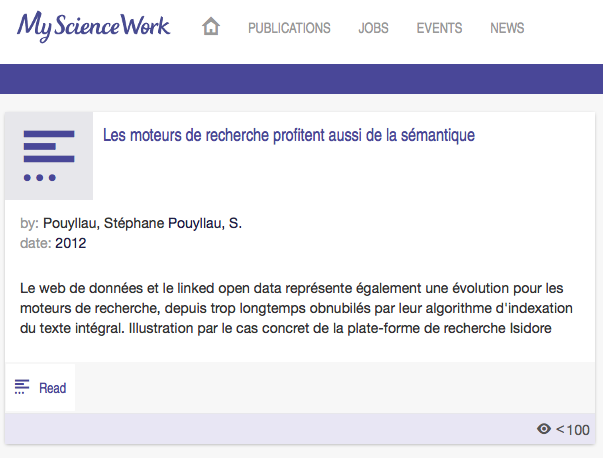
Je garde le meilleur pour la fin, dans le cas des dépôts dans HAL-SHS, aucun des liens proposés par MSW ne permet d’accéder à l’article PDF ! Je me suis créer un compte « pour aller au bout » et surprise : que des pages 404 (au 28/11/13) ! Rien ! Impossible d’atteindre les articles alors qu’ils sont bien dans HAL-SHS. Bien sur, sur ce point, il doit sans doute s’agir d’une interruption « momentanée » des liens (c’est assez classique dans moteur de recherche, lors des ré-indexations), mais quand bien même ils fonctionneraient (les liens) il est difficile de savoir que l’article est en ligne ailleurs, sur HAL-SHS : le lecteur en ligne de MSW est une petite fenêtre en pop-up. Bref, cela ne fait qu’aggraver le cas je trouve, car j’ai l’impression que l’on « cache » le fait que l’article est en ligne en AO avec des métadonnées plus riches (cf. halshs.archives-ouvertes.fr/halshs-00741328).
Pourquoi ? Imaginons un étudiant qui débute cette année en master 2 et qui s’intéresse à l’histoire des maisons fortes du Moyen-âge dans le sud-ouest (bref, moi en 1997) et qui tombe sur le moteur de recherche de MSW. Il tombe sur mon DEA et mes articles sur le Boisset et se dit qu’il doit y avoir dedans des choses à prendre et bien même avec un compte MSW il n’est pas sûr d’avoir accès aux documents ! C’est vraiment dommage car par ailleurs, ils sont sur HAL-SHS, ils sont en libre accès, ils peuvent être cités par leur url (mieux : par les identifiants pérennes handle d’Isidore que je mentionne d’ailleurs dans les métadonnées de HAL-SHS), ils mentionnent l’email et les contacts de l’auteur (au cas où l’étudiant ait envie de me contacter), ils sont reliés à d’autres données dans le cadre d’Isidore (j’espère que sa BU lui a conseillé d’utiliser Isidore)… Bref, d’un coté il a permis à MSW d’engranger de la valeur, mais il n’a pas les documents et donc pas l’information, de l’autre, il a l’information et les documents, le contact, d’autres documents en rapport avec son travail. C’est en cela que je trouve ces pratiques malhonnêtes et que je dis qu’il s’agit de la privatisation de connaissances en libre accès.
J’ai signalé cela sur twitter et MSW m’a répondu sur twitter le 21 octobre 2013 :
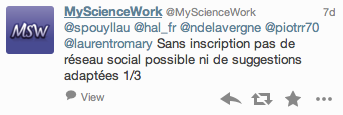
J’entends bien que le principe est la collecte d’information afin de faire du profilage de personnes, d’ailleurs construire de la valeur sur des données en libre accès pourquoi pas, cela ne me dérange pas dès lors que l’on n’en « privatise » pas l’accès. Pourquoi MSW (et les autres d’ailleurs) n’indiquent-ils pas l’origine des données, que veulent-ils faire croire ? Qu’ils ne moissonnent pas ? C’est à dire que la valeur de leur réseau ne reposerait que sur des métadonnées ? Il me semble que les acteurs publics du libre accès aux données de la recherche devraient fixer des conditions dans les réutilisations des données des AO par exemple : pourquoi ne pas proposer des licences creatives commons, Etalab ou autres ? Cela devrait faciliter les réutilisations et le fait que les données sont en accès libre sur des plateformes publiques ? Je n’entre pas dans les détails juridiques, je ne suis pas assez compétent dans ce domaine, je réfléchis simplement à un de meilleurs accès à l’information. Les plateformes telles que celle-ci ne devrait elle pas fonder leurs modèles sur la création d’enrichissements, d’éditorialisation des données ? Vous me direz, c’est ce que nous faisons déjà dans Isidore.
En conclusion, étant fonctionnaire et ayant choisi clairement le service public, j’estime que mes travaux doivent être communiqués le plus facilement possible aux publics. Je ne pense pas que les plateformes fondées sur ce modèle favorisent cela et j’estime qu’il y a là une certaine « privatisation » du savoir. Construire de la valeur sur des données gratuites est possible, mais pas en privatisant les données que les auteurs ont placées en libre accès. Ainsi, je souhaite que MSW et les autres réseaux sociaux signalent clairement dans leurs notices :
- La source des données moissonnées (archives ouvertes, éditeurs, etc.)
- La mention de la licence quand elle existe
- Le lien d’origine de la données et l’identifiant pérenne de cette dernière quand il est disponible
Sans doute cela doit nous faire réfléchir, nous acteurs publics de la recherche, aux conditions et règles que souhaitons fixer dans nos interactions (nécessaires) avec la société et donc le monde marchand. Il me semble que les réseaux sociaux, moteurs de recherche sont nécessaires afin de toucher un maximum d’utilisateur et je pense aux étudiants en particulier mais il est de notre responsabilité de favoriser la diffusion des savoirs de façon large et donc de veiller à ce que cela reste possible.
Je rappelle ici, que MSW a organisé en 2013 la semaine du libre accès…
Stéphane.
