Le 21 janvier dernier, j’ai terminé mon « cours » le cadre du master Documents électroniques et flux d’informations (dit « DEFI ») à l’université de Paris Nanterre. En juillet dernier, j’avais fait un petit billet pour annoncer le plan du cours et donner quelques pistes de lecture et d’outils que je voulais proposer aux étudiants. J’avais décidé alors de revoir entièrement la structure du cours et d’aborder plus directement et par la pratique l’utilisation des données et métadonnées structurées, collecter des informations via des API, des interfaces SPARQL, etc. Après cette dernière séance du 21 janvier, il est temps de faire un petit bilan.
Vous l’avez sans doute noté, j’ai mis cours entre guillemets dans la première phrase. En effet, premier retour, je ne pense pas avoir fait un cours, ni dans sa forme, ni sur le fond. Première limite donc, la durée. En 24h d’enseignement, c’est très (trop) court pour faire vrai un cours je pense. L’expérience de cette année montre qu’il aurait fallu un peu plus (disons 35h) pour avoir le temps d’aborder correctement l’ensemble des questions, faire d’autres développements en Python ou utiliser des outils tel que OpenRefine (que j’avais envisagé en juillet), le tout en inscrivant ça dans l’histoire du numérique, du Web, etc. Nous l’avons abordé, mais trop sommairement. D’un coté je tiens a ce que mon enseignement reste pratique avec «les mains dedans».
Deuxième limite de mon « cours » fut sa densité : l’agrégation ou plutôt l’intégration des notions de données/documents structurés (XML, stérilisation RDF), les API, Python (dans Jupyter) et l’outil Jupyter lui même en 24h… C’était un peu ambitieux sans doute. Là, j’ai vraiment pu mesurer la difficulté d’aborder tout cela, même progressivement. J’ai voulu sans doute allé trop vite au début, du coup ça j’ai été court à la fin. Je précise que je ne suis pas un enseignant universitaire, même si je délivre des enseignements depuis 1995 (en IUT, puis en maitrise, master, à Bordeaux, puis à Paris), je ne suis pas un enseignant professionnel. C’est aussi en cela que mon enseignement n’est pas vraiment un « cours », ni complètement un TD. Alors comment le définir ? À la lumière de l’expérience de cette année, ça ressemble plus à une expérience, un cheminement où l’espace d’expérimentation est la base du travail : on explore les API, on découvre les données, leurs modèles et on bricole avec. ça permet par le faire, par le test de se poser des questions plus large, jusqu’à l’évolution des métiers de la données et du document numérique.
J’ai tenté de maintenir une structure de séance avec au début : un apports de notions générales (Qu’est-ce que le Web sémantique ? Qu’est-ce que SPARQL ? Quelles différences entre verbes d’API et requêtes SPARQL ? etc.) ; puis un temps de travaux pratiques (que j’appelle bricolage, dans le sens noble du terme) avec des focus ou des retours sur certaines notions vues en début de séance (ou aux séances précédentes). En terme de méthode, j’ai plus répété cette année afin de stabiliser les notions principales en insistant sur des notions clés (à lire d’ailleurs, ce très bon retour d’expériences sur les méthodes d’enseignements à l’université par Caroline Muller, mise en ligne par Christelle Rabier). Ainsi, je suis allé moins loin, mais nous avons — je l’espère, abordé au mieux les méthodes d’utilisation des données structurées.
Troisième limite, arriver à partager mon expérience avec les étudiants et là aussi, je vois de mieux en mieux la différence entre un cours par un·e enseignant·e universitaire (qui va mettre le recul, apporter des lectures, une position critique, épistémologique) et un retour d’expérience d’un professionnel de la données qui viens du Perl (le langage verbeux qui fait sourire les étudiants, si si), des données tabulées, etc. Cela dit, l’outil Jupyter a été je pense un bon levier pour partager ensemble les expérimentations que nous avons faites sur le SPARQL endpoint et API d’ISIDORE ou de NAKALA.
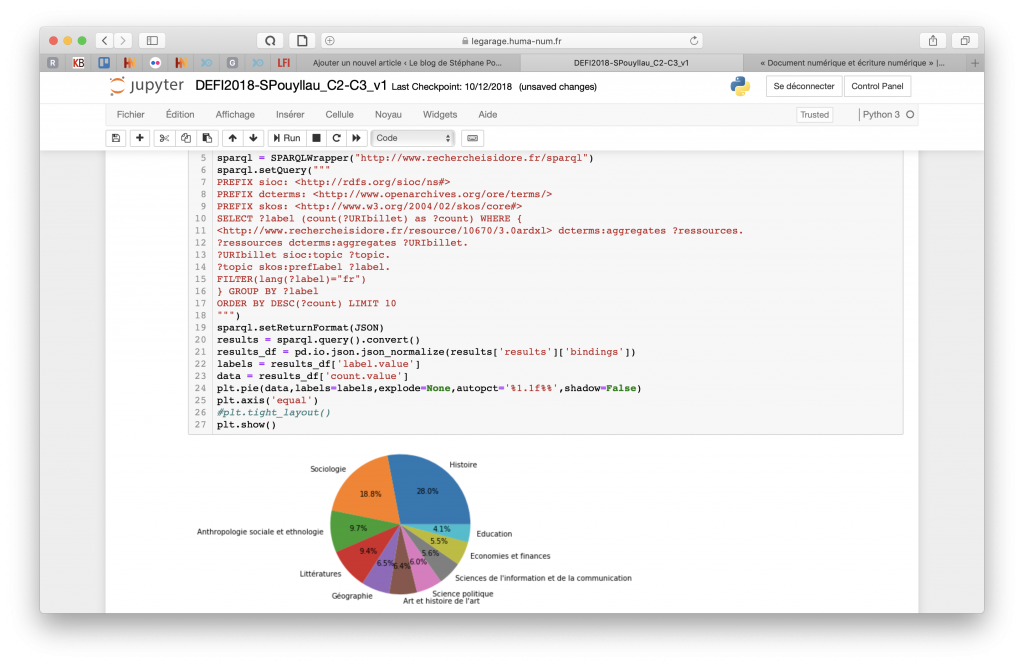
Malgré tout, nous avons réussi a développé de jolis «tableaux de bord» en Python sous Jupyter. Ici, quantifier la proportion des disciplines des 300000 billets des carnets de recherche de la plateforme Hypotheses.org :
L’expérience de cette année me permettra, je l’espère l’an prochain, d’améliorer le rythme des 8 séances et le temps interne de chacune.
Je termine en remerciant l’ensemble des étudiants de cette promo 2018-2019 pour leur participation, leurs questions et leur patience. Mon «cours» est un peu à l’image de l’immense chantier en face de l’Université Paris Nanterre ;-)
