Ouverture du colloque « Nouvelles archives numériques au Proche-Orient : le son, l’image, le film et le web » à la bibliothèque nationale du Liban — Photo S. Pouyllau, 29 mai 2019.
Le programme, très riche, m’a fait pas mal réfléchir sur les besoins méthodologiques et d’outillage pour les chercheurs et doctorants. C’est encouragement et une piqure de rappel, du terrain, pour un travail un peu réflexif sur ce que nous avons monté depuis 10-15 autour des infrastructures de recherche (OpenEdition, Huma-Num, etc.). Les « nouvelles archives » (matériaux des réseaux sociaux, vidéos Youtube, sites Web, etc.) sont des traces fragiles : en raison des politiques des plateformes, en raison des techniques utilisées pour les construire mais aussi et enfin en raison des pratiques des chercheur·es (gestion de leurs stockages, de leurs bases de données, etc).
Conférence introductive de Carla Eddé.
Elles sont fragiles aussi — naturellement, par les aléas politiques et géopolitiques d’une région complexe. En ce sens la conférence très dynamique de Carla Eddé (historienne et vice-rectrice pour les relations internationales à l’Université Saint-Joseph) sur « Archives, mémoire, histoire » a très bien montré la construction actuelle (et la non-construction) de la mémoire du Liban contemporain, de la mémoire de la guerre civile du Liban (1975-1990) autour de la question « des gouts de l’archive » dans le Liban d’aujourd’hui. En ce sens j’y ai vu des connexions avec le programme de recherche « Le goût de l’archive à l’ère numérique ».
La fragilité des données numériques et leurs mises en archive, ont été particulièrement bien illustrés par les communications de Cécile Boex (EHESS, Césor) sur « Archiver les vidéos vernaculaires de la révolte et du conflit en Syrie : enjeux éthiques et politiques » et Zara Fournier (doctorante en géographie à l’université de Tours, labo CITERES) sur « Désirs d’ailleurs et d’avant : les militants de la mémoire et le Web au Sud du Liban ». En conclusion, la question de la compréhension et de la maitrise des méthodes numériques pour la bonne gestion des données de terrain, mais aussi la compréhension des interconnexions des outils forgés a été très bien résumée par Kamel Doraï, directeur du département des études contemporaines de l’Ifpo.
Ponctué de projection de film, dont l’impressionnant « Tadmor » de Monika Borgmann et Lokman Slim (bientôt en salle à Paris). J’espère que le colloque donnera lieu à une publication d’actes, ou des enregistrments qui ont été effectué par Jean-Christophe Peyssard (Ifpo) et Véronique Ginouvès (MMSH).
Le 21 janvier dernier, j’ai terminé mon « cours » le cadre du master Documents électroniques et flux d’informations (dit « DEFI ») à l’université de Paris Nanterre. En juillet dernier, j’avais fait un petit billet pour annoncer le plan du cours et donner quelques pistes de lecture et d’outils que je voulais proposer aux étudiants. J’avais décidé alors de revoir entièrement la structure du cours et d’aborder plus directement et par la pratique l’utilisation des données et métadonnées structurées, collecter des informations via des API, des interfaces SPARQL, etc. Après cette dernière séance du 21 janvier, il est temps de faire un petit bilan.
Utilisation de Jupyter Hub le 17 décembre 2018 avec les masters DEFI 2018-2019. Photo : Stéphane Pouyllau
Vous l’avez sans doute noté, j’ai mis cours entre guillemets dans la première phrase. En effet, premier retour, je ne pense pas avoir fait un cours, ni dans sa forme, ni sur le fond. Première limite donc, la durée. En 24h d’enseignement, c’est très (trop) court pour faire vrai un cours je pense. L’expérience de cette année montre qu’il aurait fallu un peu plus (disons 35h) pour avoir le temps d’aborder correctement l’ensemble des questions, faire d’autres développements en Python ou utiliser des outils tel que OpenRefine (que j’avais envisagé en juillet), le tout en inscrivant ça dans l’histoire du numérique, du Web, etc. Nous l’avons abordé, mais trop sommairement. D’un coté je tiens a ce que mon enseignement reste pratique avec «les mains dedans».
Deuxième limite de mon « cours » fut sa densité : l’agrégation ou plutôt l’intégration des notions de données/documents structurés (XML, stérilisation RDF), les API, Python (dans Jupyter) et l’outil Jupyter lui même en 24h… C’était un peu ambitieux sans doute. Là, j’ai vraiment pu mesurer la difficulté d’aborder tout cela, même progressivement. J’ai voulu sans doute allé trop vite au début, du coup ça j’ai été court à la fin. Je précise que je ne suis pas un enseignant universitaire, même si je délivre des enseignements depuis 1995 (en IUT, puis en maitrise, master, à Bordeaux, puis à Paris), je ne suis pas un enseignant professionnel. C’est aussi en cela que mon enseignement n’est pas vraiment un « cours », ni complètement un TD. Alors comment le définir ? À la lumière de l’expérience de cette année, ça ressemble plus à une expérience, un cheminement où l’espace d’expérimentation est la base du travail : on explore les API, on découvre les données, leurs modèles et on bricole avec. ça permet par le faire, par le test de se poser des questions plus large, jusqu’à l’évolution des métiers de la données et du document numérique.
J’ai tenté de maintenir une structure de séance avec au début : un apports de notions générales (Qu’est-ce que le Web sémantique ? Qu’est-ce que SPARQL ? Quelles différences entre verbes d’API et requêtes SPARQL ? etc.) ; puis un temps de travaux pratiques (que j’appelle bricolage, dans le sens noble du terme) avec des focus ou des retours sur certaines notions vues en début de séance (ou aux séances précédentes). En terme de méthode, j’ai plus répété cette année afin de stabiliser les notions principales en insistant sur des notions clés (à lire d’ailleurs, ce très bon retour d’expériences sur les méthodes d’enseignements à l’université par Caroline Muller, mise en ligne par Christelle Rabier). Ainsi, je suis allé moins loin, mais nous avons — je l’espère, abordé au mieux les méthodes d’utilisation des données structurées.
Troisième limite, arriver à partager mon expérience avec les étudiants et là aussi, je vois de mieux en mieux la différence entre un cours par un·e enseignant·e universitaire (qui va mettre le recul, apporter des lectures, une position critique, épistémologique) et un retour d’expérience d’un professionnel de la données qui viens du Perl (le langage verbeux qui fait sourire les étudiants, si si), des données tabulées, etc. Cela dit, l’outil Jupyter a été je pense un bon levier pour partager ensemble les expérimentations que nous avons faites sur le SPARQL endpoint et API d’ISIDORE ou de NAKALA.
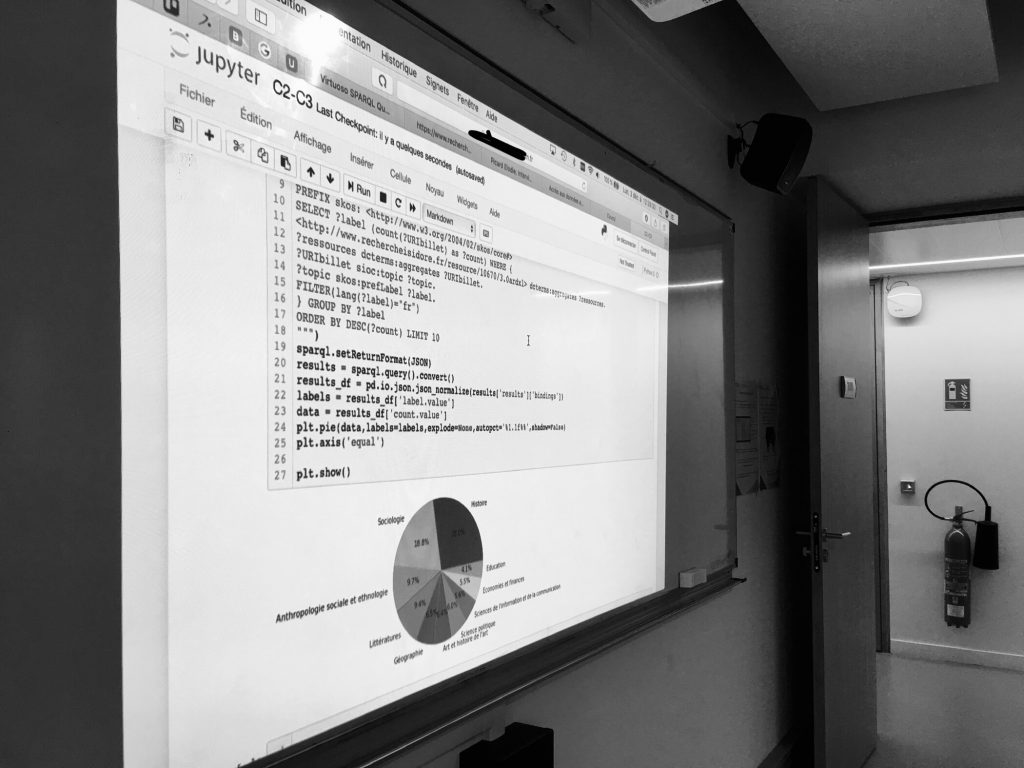
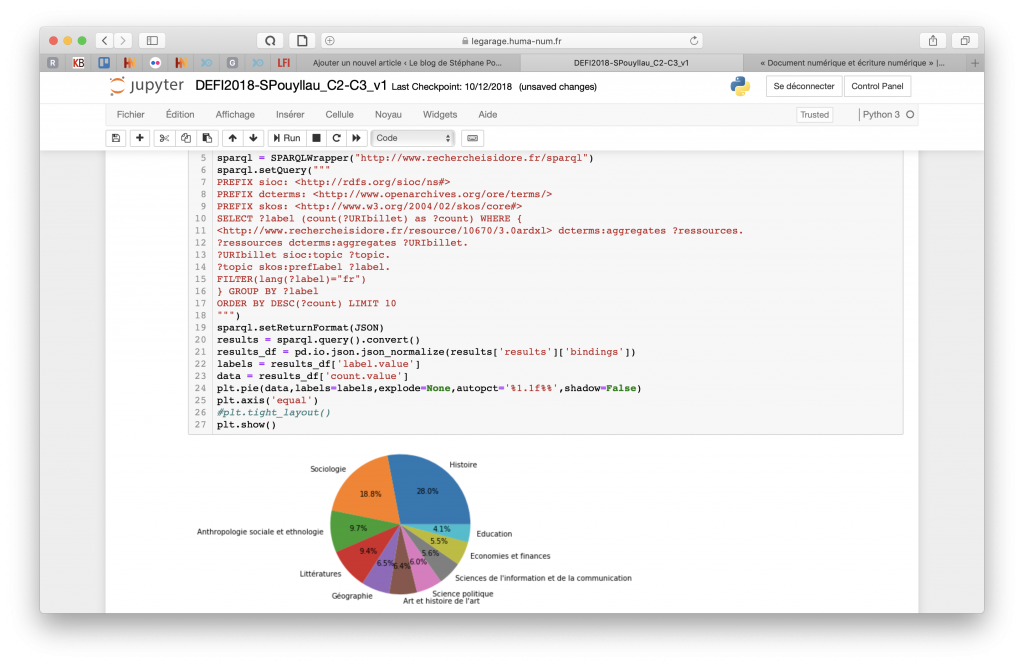
Malgré tout, nous avons réussi a développé de jolis «tableaux de bord» en Python sous Jupyter. Ici, quantifier la proportion des disciplines des 300000 billets des carnets de recherche de la plateforme Hypotheses.org :
Utilisation de Jupiter Hub pour les DEFI 2018-2019.
L’expérience de cette année me permettra, je l’espère l’an prochain, d’améliorer le rythme des 8 séances et le temps interne de chacune.
Je termine en remerciant l’ensemble des étudiants de cette promo 2018-2019 pour leur participation, leurs questions et leur patience. Mon «cours» est un peu à l’image de l’immense chantier en face de l’Université Paris Nanterre ;-)
Depuis quelques mois, je constate l’émergence d’une nouvelle « génération » d’historiens et historiennes. Il me semble qu’elle est apparue au détour des THATCamps sur les humanités numérique des années 2010-2012. J’y avais constaté la présence d’historiens et d’historiennes (et de nombreux doctorants et doctorantes) des disciplines de l’histoire moderne et contemporaine avides de comprendre le mouvement des humanités numériques. Plus attentif à porter mes deux communautés de formation (histoire médiévale et archéologie) vers les humanités numériques et surtout en raison de la création d’Huma-Num, je n’ai vu que récemment l’envol de cette une nouvelle « histoire à de l’ère numérique ». Si les historiens et historiennes ont depuis longtemps forgée des bases de données, gérés et utilisés des données quantitatives et qualitatives, il me semble qu’il souffle un vent un peu nouveau depuis quelques années en particulier sur trois points : la réflexion sur les méthodes de l’historien doublée une réflexion épistémologique assez poussée sur les sources de l’historien ; la place de l’outil (au sens large) dans la recherche et l’enseignement de l’histoire à l’université ; enfin, résultante de ce dernier point, le renouvellement des pratiques de l’enseignement de l’histoire dans le supérieur.
De nouvelles sources et un recul à prendre
Quand Frédéric Clavert utilise comme source de ses travaux des tweets, il fait entrer de nouveaux contenus (courts, liés à un contexte temporel, etc.) dans la bibliothèque du chercheur. Il y fait aussi entrer de la technique, de la documentation informatique, du code qui entraine obligatoire la nécessité d’une épistémologie des contenants au même titre que de celle des contenus.
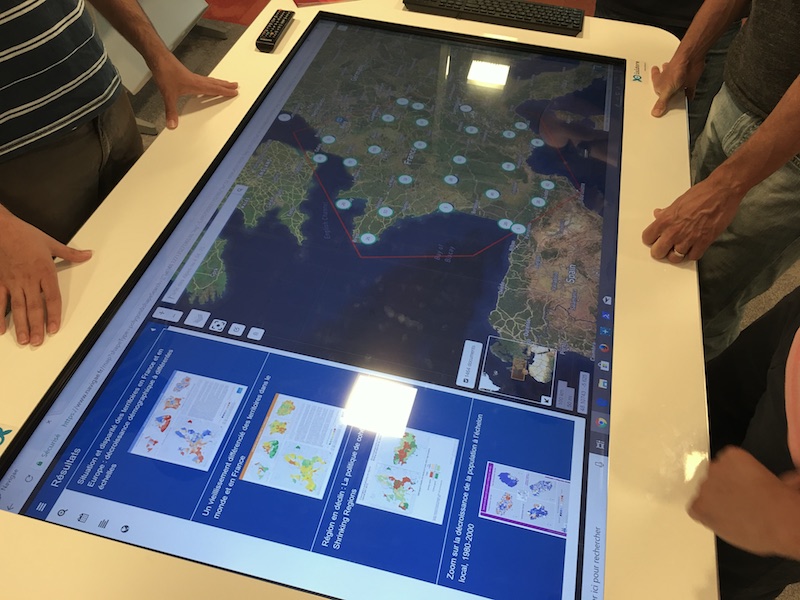
Consultation collective d’archives historiques et cartographiques sur ISIDORE tactile, 2018 – Photo : S. Pouyllau.
Construire le réservoir de connaissance de l’historien à partir d’une API (ici celle de Twitter) implique une « diplomatique de l’API et du code » qui va traiter les données et une explicitation des choix qui seront fait par l’historien ou historienne des structures de la base de données. Même si de nos jours ce travail est mal pris en compte dans l’évaluation de la qualité des travaux, ce n’est qu’un moment. Demain, la « diplomatique de l’API » sera au centre de l’attention portée à compréhension des conclusions et connaissances nouvelles avancées par cette profession.
L’outil dans la recherche et dans l’enseignement
Quand Franziska Heimburger, Émilien Ruiz ou Caroline Muller diffusent leurs impressions, conseils, « trucs et astuces » et réflexions sur Zotero et autres outils, via leurs différents carnets de recherche, blogs, sites web, conférences, journées d’études, ils/elles placent l’outil numérique dans la recherche. Le programme informatique est dans leurs mains d’historiens et historiennes et c’est par leurs critiques et impressions qu’ils entrent dans le cartable de tous les futurs historiens et historiennes qu’ils/elles forment. Par leurs essais, pour leurs propres besoins, entourés (ou pas) de personnels d’accompagnement des SHS, ils/elles ont construit des protocoles du traitement des données de l’histoire. Ce n’est par la confrontation à la donnée et aux outils standards et finalement assez loin des grandes manœuvres, parfois un peu oppressante, de la normalisation et de l’internationalisation des pratiques par l’innovation, qu’ils/elles forgent leurs applications et leurs chaines de traitement des données.
Maintenant, ils/elles sont dans le partage de ces protocoles, ils/elles « prescrivent » et assument de le faire sans positionner ce savoir en tant que « science auxiliaire », c’est à dire à « coté » de l’histoire. Il me semble qu’il y là quelque chose d’intéressant. En effet, assumer d’être producteur de connaissance, forgeurs d’outils pour produire ces savoirs tout en assurant la critique, la promotion et l’enseignement de l’évolution des techniques de son propre métier — dans un domaine où l’on sépare encore largement le savoir érudit de comment il est produit, me semble relever d’une avancée considérable et d’une aventure passionnante. Car au-delà de l’important renouvellent les problématiques de recherche qu’ils/elles portent, ils/elles font évoluer les choses.
Enseigner à l’ère numérique
Quand Caroline Muller ou Martin Grandjean enseignent, ils intègrent dans leurs enseignements les méthodes et les (ou leurs) outils numériques. Ils modifient fortement et pour longtemps dans la façon d’enseigner l’histoire même si quelques retours en arrière peuvent être possibles malheureusement (sans doute dues à des contraintes passagères qu’à des réactions d’opposition construites et réfléchies).
Plusieurs billets ont récemment très bien détaillé je trouve cette appropriation du numérique dans les métiers de l’enseignement supérieur et de la recherche en histoire : Emilien Ruiz l’a très bien exprimé dans “Historien·ne·s numériques : gare au SSPQ !” :
« Je suis, depuis longtemps, convaincu de la nécessité d’un ancrage disciplinaire de la formation numérique des étudiants : pour ne pas être dépendants des outils, pour se garder tant des envolées lyriques que des rejets dédaigneux, c’est en historiennes et historiens que nous devons appréhender les instruments informatiques et les ressources numériques à notre disposition. »
« Il était donc certainement nécessaire de passer par cette étape du champ séparé des « humanités numériques », même s’il a peut-être contribué, en retour, à instituer l’idée que c’est un monde à part, et retardé l’intégration aux pratiques et formations disciplinaires classiques. »
J’adhère à cette analyse.
Ces billets sont des marqueurs, bien visibles et pour une large audience, des transformations qui s’opèrent actuellement dans les parcours de L et M à l’université. En disant cela il me sera sans doute opposé l’idée qu’il s’agit là de parcours particuliers dus à la personnalité de quelques-uns ou quelques-unes, que ce n’est pas un mouvement de masse, que l’université n’est pas (ou n’est plus) en mesure d’en faire un enseignement pour tous, que les pratiques mettront 25 ans à changer, qu’il y a la question des moyens et de la formation continue du personnel enseignant post-recrutement, etc. Je sais tout cela.
Cependant je ne veux pas attendre que l’université s’y mette pour souligner l’importance du travail fait en ce moment par ces quelques personnes qui sont en train de faire évoluer sans pour autant être dans la « disruption ». D’autres me diront que du point de vue des métiers de la connaissance (documentation, bibliothèques, archives) cela n’est pas nouveau et qu’il y a encore beaucoup de travail. Je répondrai, tant mieux ! Cette évolution du métier d’historiens et historiennes que porte ce petit groupe vous permettra sans doute de faire évoluer les vôtres ! Cela faut d’ailleurs pour les sciences du numériques et la mise en oeuvre des infrastructures de recherche : délivrer de la « puissance numérique » doit tenir compte de ces évolutions et il faut éviter de plaquer des pratiques numériques issues d’autres communautés car — pour l’histoire, ces pratiques de l’ère numérique sont clairement en train d’être portées, d’être discutées par les enseignants-chercheurs du domaine. On fait un pas de coté, on observe et on accompagne.
IBM 129 Card Data Recorder (IBM System/370, 1971) – Photo : S. Pouyllau
Comme je dis depuis longtemps maintenant, faire de la recherche en SHS, depuis l’arrivée de l’ordinateurs (1972-1989), puis du Web (1989-), puis de l’ère numérique (que je fais débuter à l’arrivée des smartphones — en gros en 2007, et qui ont complété le carnet d’archives), c’est mixer les métiers. C’est faire à minima de 20 à 30% du chemin vers les autres métiers : de l’informatique, de la donnée, de l’archive. Le fait que ce mouvement irrigue en temps réel les enseignements est une chose importante car cela veut dire évidement que l’agilité et l’autonomie face aux données et aux outils s’améliore pour les historiens et historiennes, que la critique des méthodes et des outils se renforce et que les thématiques de recherche seront interrogées différemment.
En conclusion, si je me permets de mettre la lumière sur ces quelques personnes, pour certains et certaines croisés récemment, je le fais volontairement car il me semble qu’ils/elles sont plus assis sur la tête que sur les épaules des géants. Ce que je vois de cette évolution de l’historien me plait car elle place le numérique au bon niveau au bon moment. Surtout, le plus important à mes yeux, c’est que le bon niveau et le bon moment sont le fruit de leur travail mixant leurs pratiques et l’import de savoirs extérieurs (informatique, etc.) dans ce qu’ils/elles définissent comme le périmètre de l’historien/historienne.
Je veux par ce billet les remercier (eux et tous ceux qui ce placent de façon raisonnée dans l’ère numérique) d’avoir compris qu’il ne fallait pas forcement cultiver le champ qu’on leur destinait, et que pour cela il fallait mettre à jour leurs outils et la façon de les utiliser tout en s’imprégnant des travaux, des erreurs faites et des contraintes de leurs temps. Ils/elles sont des aussi des pionniers.
Stéphane Pouyllau.
Note : le billet contient sans doute encore des coquilles, merci de me les signaler en commentaire.
J’enseigne depuis quelques années à l’université de Paris Nanterre, en tant que « professionnel extérieur », dans le cadre du master « Documents électroniques et flux d’informations » (dit « DEFI »). Mon cours s’intitule « Document structuré et écriture numérique » et pour l’an prochain (2018-2019) j’en ai entièrement revue la structure.
Description du cours :
Le cours portera sur l’écriture numérique dans le contexte de l’open data et de la science ouverte (open science) car en effet de nos jours les publications (articles scientifiques, thèses, mémoires, rapports, littérature grise) embarquent des données issues de bases de connaissances, de bases de données, d’API, du Web sémantique. Dans ce contexte, les publications embarquent de nos jours non seulement du texte et des références bibliographiques, mais aussi des données (sérielles, documents, etc) et des programmes informatiques qui traitent ces dernières. Quel sont les enjeux de ces nouvelles forme de publication ? Comment « écrire » des programmes dans un document ? Quels rôles jouent les vocabulaires documentaires mais aussi les API et les SPARQL endpoint ? Quels sont les standards qui s’en dégagent ? Est-ce une nouvelle forme de publication ? Comment pérenniser ces documents ? A l’aide de données issues des projets ISIDORE, NAKALA, WikiData, le cours permettra d’acquérir :
Les enjeux des données dans la publication scientifique et technique (2 séances)
La conception de publications de données (2 séances)
Le traitement de données (2 séances)
La compréhension des vocabulaires documentaires structurés (1 séance)
Les enjeux de l’interopérabilité des métadonnées et données (1 séances)
Enseignant : Stéphane Pouyllau, ingénieur de recherche au CNRS, directeur technique d’Huma-Num (très grande infrastructure de recherche pour les sciences humaines et sociales numériques)
Bibliographie (non exhaustive) :
Bermès, E., A. Isaac et G. Poupeau (2013) : Le Web sémantique en bibliothèque, Collection Bibliothèques, Paris.
Gandon, F., C. Faron-Zucker et O. Corby (2012) : Le Web sémantique: comment lier les données et les schémas sur le web ?, InfoPro. Management des systèmes d’information, ISSN 1773-5483, Paris, France.
Passant, A. (2009) : Technologies du Web Sémantique pour l’Entreprise 2.0, Mémoires, Thèses et HDR, ABES.
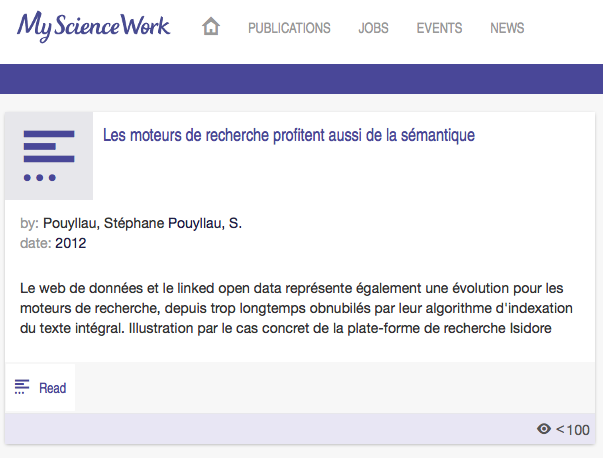
Pouyllau, S. (2012) : “Les moteurs de recherche profitent aussi de la sémantique”, Documentaliste – Sciences de l’Information, 48, 4, 36‑37.
Pouyllau, S. (2013) : “Web de données, big data, open data, quels rôles pour les documentalistes? (French)”, Documentaliste: Sciences de l’Information, 50, 3, 32‑33.
Pouyllau, S. (2014) : sp.Blog — Utiliser Isidore pour ses propres données (quand on est, par exemple, dans un labo) (http://blog.stephanepouyllau.org/646).
Je viens d’apprendre le décès brutal de Louise Merzeau. Elle m’avait invité à participer au séminaire Ecrilecture en 2012 et je me souviens de cette discussion si forte et riche qui s’y était développé. Grace à Louise, j’ai rencontre Marcello Vitali-Rosati, Vincent Larrivière, etc. mes contacts du Québec avec qui je travaille aujourd’hui. J’ai croisé plusieurs fois Louise Merzeau dans des réunions, ateliers, et j’avais été marqué par la richesse de ses analyses, toujours très précises, appelant à réfléchir. Elle m’avait souvent questionné sur les « traces » dans le cadre du projet ISIDORE, et particulièrement lors du séminaire Ecrilecture. Ses questions étaient si constructives. Je pense à ses proches, à ses étudiants. Louise va nous manquer.
Lancé en 2010 par le Centre pour la communication scientifique directe du CNRS et avec l’aide du TGE Adonis (devenu depuis Huma-Num) et du CN2SV, MédiHAL est une archive ouverte de photographies, d’images, et maintenant de vidéo qui compte plus de 24000 entrées venant principalement du domaine des SHS (mais pas que !). Ayant participé à sa création avec S. Kilouchi, D. Charnay et L. Capelli, je suis très content du chemin parcouru par ce projet, modeste au départ, qui fut réalisé rapidement (quelques mois) et finalement avec assez peu de financement (uniquement les salaires des acteurs concernés).
MédiHAL, vue en 2016
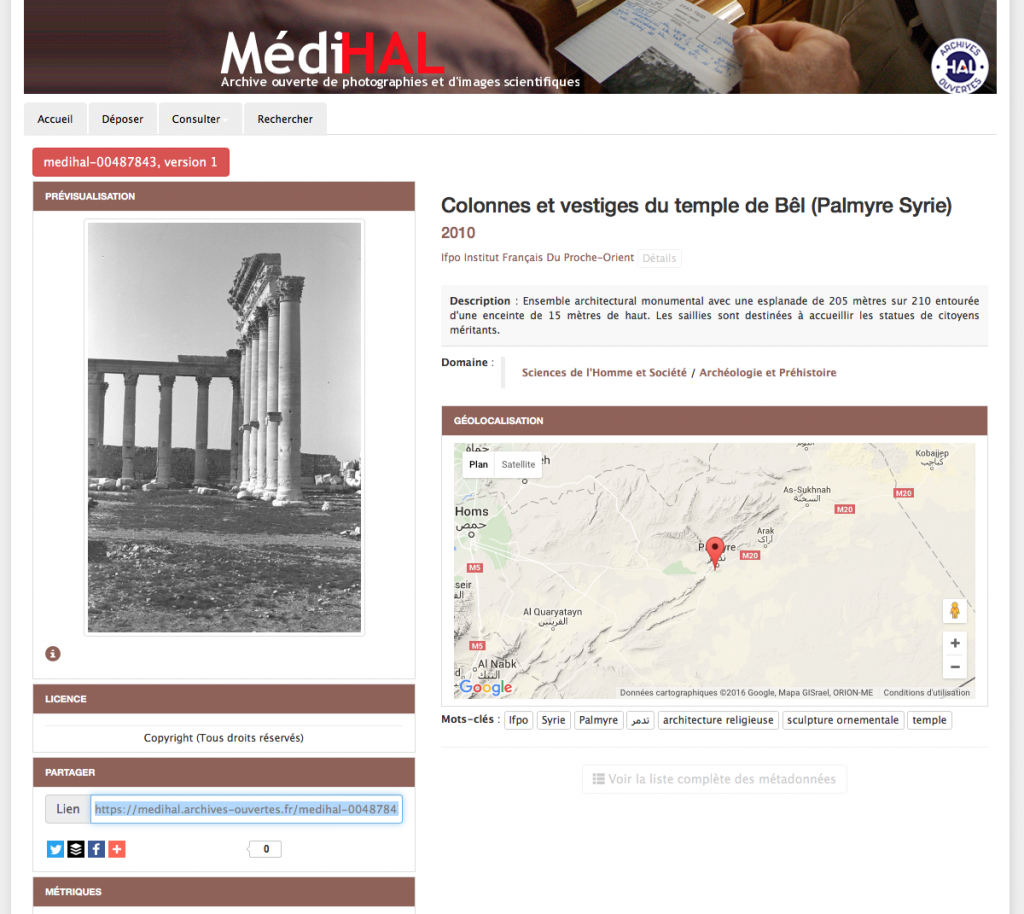
Après 5 ans de travail autour de MédiHAL, principalement dans l’animation/promotion de cet objet et dans la validation des dépôts, et parce que mes occupations actuelles au sein d’Huma-Num sont très intenses, j’ai estimé qu’il était temps de passer la main à d’autres. C’est désormais, le CCSD qui assurera la validation des dépôts dans MédiHAL ainsi que la définition des évolutions futures de la plateforme. Beaucoup de personnes ont contribué à améliorer MédiHAL depuis le début et j’espère que cela continuera car si l’outil se veut simple, il y aura toujours des choses nouvelles à proposer autour des archives ouvertes de données (en particulier en lien avec les publications). MédiHAL contient des images et des photographie qui ont aujourd’hui une valeur scientifique et patrimoniale particulière qui raisonnent avec l’actualité, en particulier les séries de photographies du temple de Bêl à Palmyre (Syrie) issues des collections de l’Institut Français Du Proche-Orient (ifpo).
Palmyre, Temple de Bel
J’ai été très heureux de participer à ce projet et je lui souhaite plein de bonnes choses pour le futur ! Et via ISIDORE, qui moissonne MédiHAL et HAL, je regarderai avec bienveillance grandir le corpus de MédiHAL !
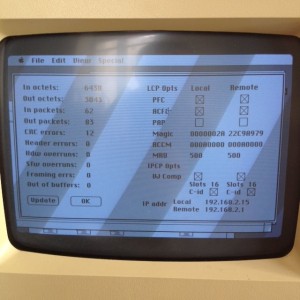
Après l’opération « on échange des fichiers entre un Macintosh Plus de 1986 et un MacBook Pro » via Zterm et un cable série…
… voici l’opération « un Macintosh Plus de 1986 se connecte à Internet » réalisée ! J’avais mis cela sur Facebook il y a quelques semaines et j’en fait un mini billet pour les amateurs de rétro-informatique (je ferai un billet plus détaillé, avec captures d’écran « cathodique de 9 pouces » dans quelques temps).
Pour information le Macintosh Plus date de 1986, il a 4 méga-octets de RAM (!) et tourne sous Mac OS 6.0.8 et se connecte à Internet via MacPPP + MacTCP et une connexion série sur un Raspberry Pi équipé du programme SLIRP qui fait le pont vers internet (d’un port série à du RJ45). Le Raspberry Pi (modèle B) tourne sous Raspbian. SLIRP simule une connexion PPP et fait le pont vers le réseau TCP/IP.
Résultat : on surfe à la vitesse ultra rapide de… 19200 bit/s (19 kbit/s) ! Cela est suffisant pour faire du… FTP ou du Telnet (haaaa NCSA Telnet !).
Cela permet de se rendre compte qu’entre 1990 et 1995 se connecter à Internet et à ses services ( gopher, WWW, etc.) n’était pas si évident pour qui avait investi dans les années 80 dans un macintosh. Il est intéressant de voir aussi que les « couches » de protocoles, services étaient encore bien visibles et séparées les unes des autres. PPP d’un coté pour établir la connexion, MacTCP pour la couche TCP/IP, MacWWW (de Robert Cailliau !), Eudora pour les emails (et encore sur le port 25 en SMTP c’est dur aujourd’hui… Mais mon synology est là pour faire le pont…)… Refaire vivre la technologie d’il y a juste 20 ans n’est pas simple mais on y arrive.
Prochaine étape :
1/ Mettre en place MacWeb premier navigateur web pour Mac OS ! Mais là j’ai besoin de passer le Macintosh Plus sous system 7.0.x, et là, les 4 Mio de RAM vont être justes…
2/ Ecrire un billet dans mon blog présentant tout cela !
Bonjour,
Je signale la parution chez Fyp éditions de l’ouvrage dirigé par Olivier Le Deuff et dans lequel j’ai contribué (un petit peu) : « Le temps des humanités digitales, la mutation des sciences humaines et sociales ». Ce livre collectif donne des pistes pour découvrir et s’approprier le mouvement des humanités « digitalo-numériques ». Au fil des chapitres, il est aussi clair que l’on sent bien que le « poids » du Web est de plus en plus important pour le secteur de la recherche en SHS : les outils de traitements, documentations et visualisations passent tous par le Web (et donc par le protocole HTTP). Cela renforce l’importance des enjeux de la bonne compréhension de ce dernier (ex. : le Web et Internet, c’est différent !) en particulier à l’heure du web des données. Bonne lecture !
Stéphane.
Résumé éditeur : « Les humanités digitales se situent à la croisée de l’informatique, des arts, des lettres et des sciences humaines et sociales. Elles s’enracinent dans un mouvement en faveur de la diffusion, du partage et de la valorisation du savoir. Avec leur apparition, les universités, les lieux de savoir et les chercheurs vivent une transformation importante de leur mode de travail. Cela entraîne une évolution des compétences et des pratiques. Cet ouvrage explique les origines des humanités digitales et ses évolutions. Il décrit leurs réussites, leurs potentialités, leur rapport à la technique et comment elles transforment les sciences humaines, la recherche et l’enseignement. Il examine les enjeux des nouveaux formats, modes de lecture, et des outils de communication et de visualisation. Ce livre permet d’aller plus loin dans vos pratiques et vos réflexions. Le temps des humanités digitales est venu ! »
Sous la direction d’Olivier Le Deuff. Avec les contributions de Milad Doueihi, Jean-Christophe Plantin, Olivier Le Deuff, Frédéric Clavert, Frédéric Kaplan, Mélanie Fournier, Nicolas Thély, Marc-Antoine Nuessli, René Audet, Stéphane Pouyllau, Frank Cormerais, Sylvain Machefert.
A l’occasion de la semaine du libre accès (open access week, du 21/25 octobre 2013), j’ai découvert un peu plus le projet MyScienceWork (MSW) qui se veut être un projet de réseau social centré sur les sciences. Ces réseaux ne sont pas nouveaux, ils sont assez nombreux : de Researchgate.org à Academia.edu. De façon plus claire, sur la première page de son site web, MSW propose un moteur de recherche assez large et qui affiche au compteur 28 millions de publications, … Certains chercheurs me diront que c’est spectaculaire, merveilleux et qu’il y a tout dans ces moteurs de recherche de réseaux sociaux mais je répondrai qu’il est facile d’afficher 28 millions de publications : il suffit de moissonner soit le web et de trier les sources, soit des entrepôts d’archives ouvertes selon le protocole OAI-PMH et de faire comme OAIster.org il y a quelques années : grossir, grossir, grossir… Ensuite il faut bien sur une interface et des filtres (facettes, etc.). Il est facile de faire du chiffre dans ce domaine là quand l’OAI-PMH permet le moissonnage gratuit de métadonnées et la récupération – par exemple – des articles en PDF qui y sont déposés. Testant le moteur de recherche de MSW justement, quelle ne fut ma « surprise » de voir que ce réseau – tout en se réclamant de libre accès (leur slogan est « MyScienceWork: Frontrunner in Open Access » – en malmène largement les principes ; voir construit son projet en privatisant de la connaissance en libre accès.
Comme beaucoup de personnes, à la vue d’un outil de recherche en ligne, mon narcissisme reprend du poil de la bête, je requête MSW sur mon patronyme : un grand nombre de mes articles, pré-publications, documents sortent. Je me dis alors qu’ils moissonnent HAL-SHS, l’archive ouverte nationale, et que dont voilà une belle initiative valorisant les contenus en libre accès. Hélas, voulant accéder au document PDF de l’un de mes papiers (en libre accès), je découvre qu’il faut avoir un compte MSW pour télécharger le document ou le lire en ligne (c’est à dire utiliser le lecteur PDF de MSW). Résumons, alors que mes articles sont libre accès dans HAL-SHS et au passage que je me suis battu (avec les éditeurs) pour qu’ils le soient, MSW demande aux utilisateurs venant sur leur moteur de recherche de se créer un compte pour voir mes papiers ! Sans compte dans MSW impossible de télécharger l’article PDF ou de le lire.
Pire, il n’est même pas signalé l’origine des publications : ni source, ni référence d’éditeurs, et donc HAL-SHS n’est même pas mentionné ! L’url pérenne fournie par HAL-SHS n’est pas indiquée non plus, le lien proposé pointe sur une adresse « maison » de MSW qui n’a rien de pérenne (elle est explicite, mentionne le nom du réseau : http://www.mysciencework.com/publication/show/1107184/les-moteurs-de-recherche-profitent-aussi-de-la-semantique). Bref, on ne sait pas d’où vient l’article, ni dans quoi il a été publié ! Parfois une mention « In » apparait, mais pas dans mes articles. Voir la différence de traitement du même papier que j’ai déposé dans HAL-SHS et moissonné dans MSW (éditeur mentionné par ex. dans mon dépot HAL-SHS) :
Je garde le meilleur pour la fin, dans le cas des dépôts dans HAL-SHS, aucun des liens proposés par MSW ne permet d’accéder à l’article PDF ! Je me suis créer un compte « pour aller au bout » et surprise : que des pages 404 (au 28/11/13) ! Rien ! Impossible d’atteindre les articles alors qu’ils sont bien dans HAL-SHS. Bien sur, sur ce point, il doit sans doute s’agir d’une interruption « momentanée » des liens (c’est assez classique dans moteur de recherche, lors des ré-indexations), mais quand bien même ils fonctionneraient (les liens) il est difficile de savoir que l’article est en ligne ailleurs, sur HAL-SHS : le lecteur en ligne de MSW est une petite fenêtre en pop-up. Bref, cela ne fait qu’aggraver le cas je trouve, car j’ai l’impression que l’on « cache » le fait que l’article est en ligne en AO avec des métadonnées plus riches (cf. halshs.archives-ouvertes.fr/halshs-00741328).
Pourquoi ? Imaginons un étudiant qui débute cette année en master 2 et qui s’intéresse à l’histoire des maisons fortes du Moyen-âge dans le sud-ouest (bref, moi en 1997) et qui tombe sur le moteur de recherche de MSW. Il tombe sur mon DEA et mes articles sur le Boisset et se dit qu’il doit y avoir dedans des choses à prendre et bien même avec un compte MSW il n’est pas sûr d’avoir accès aux documents ! C’est vraiment dommage car par ailleurs, ils sont sur HAL-SHS, ils sont en libre accès, ils peuvent être cités par leur url (mieux : par les identifiants pérennes handle d’Isidore que je mentionne d’ailleurs dans les métadonnées de HAL-SHS), ils mentionnent l’email et les contacts de l’auteur (au cas où l’étudiant ait envie de me contacter), ils sont reliés à d’autres données dans le cadre d’Isidore (j’espère que sa BU lui a conseillé d’utiliser Isidore)… Bref, d’un coté il a permis à MSW d’engranger de la valeur, mais il n’a pas les documents et donc pas l’information, de l’autre, il a l’information et les documents, le contact, d’autres documents en rapport avec son travail. C’est en cela que je trouve ces pratiques malhonnêtes et que je dis qu’il s’agit de la privatisation de connaissances en libre accès.
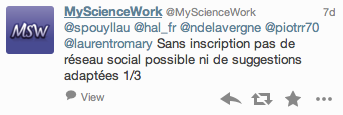
J’ai signalé cela sur twitter et MSW m’a répondu sur twitter le 21 octobre 2013 :
J’entends bien que le principe est la collecte d’information afin de faire du profilage de personnes, d’ailleurs construire de la valeur sur des données en libre accès pourquoi pas, cela ne me dérange pas dès lors que l’on n’en « privatise » pas l’accès. Pourquoi MSW (et les autres d’ailleurs) n’indiquent-ils pas l’origine des données, que veulent-ils faire croire ? Qu’ils ne moissonnent pas ? C’est à dire que la valeur de leur réseau ne reposerait que sur des métadonnées ? Il me semble que les acteurs publics du libre accès aux données de la recherche devraient fixer des conditions dans les réutilisations des données des AO par exemple : pourquoi ne pas proposer des licences creatives commons, Etalab ou autres ? Cela devrait faciliter les réutilisations et le fait que les données sont en accès libre sur des plateformes publiques ? Je n’entre pas dans les détails juridiques, je ne suis pas assez compétent dans ce domaine, je réfléchis simplement à un de meilleurs accès à l’information. Les plateformes telles que celle-ci ne devrait elle pas fonder leurs modèles sur la création d’enrichissements, d’éditorialisation des données ? Vous me direz, c’est ce que nous faisons déjà dans Isidore.
En conclusion, étant fonctionnaire et ayant choisi clairement le service public, j’estime que mes travaux doivent être communiqués le plus facilement possible aux publics. Je ne pense pas que les plateformes fondées sur ce modèle favorisent cela et j’estime qu’il y a là une certaine « privatisation » du savoir. Construire de la valeur sur des données gratuites est possible, mais pas en privatisant les données que les auteurs ont placées en libre accès. Ainsi, je souhaite que MSW et les autres réseaux sociaux signalent clairement dans leurs notices :
La source des données moissonnées (archives ouvertes, éditeurs, etc.)
La mention de la licence quand elle existe
Le lien d’origine de la données et l’identifiant pérenne de cette dernière quand il est disponible
Sans doute cela doit nous faire réfléchir, nous acteurs publics de la recherche, aux conditions et règles que souhaitons fixer dans nos interactions (nécessaires) avec la société et donc le monde marchand. Il me semble que les réseaux sociaux, moteurs de recherche sont nécessaires afin de toucher un maximum d’utilisateur et je pense aux étudiants en particulier mais il est de notre responsabilité de favoriser la diffusion des savoirs de façon large et donc de veiller à ce que cela reste possible.
Je rappelle ici, que MSW a organisé en 2013 la semaine du libre accès…
Alors qu’au THATCamp de St Malo une partie de la « non-communauté » des humanités numériques structure une association francophone, la professionnalisation de ce mouvement s’accélère. Lors du dîné d’hier soir la nécessité d’une revue augmentée est apparue évidente (en tous cas pour moi). Une revue augmentée est une revue où il est possible de publier dans les articles, ou à coté des articles, des données, des programmes, des codes, qui permettent aux lecteurs de suivre le cheminement méthodologie en ayant les moyens de reproduire les démonstration, du moins de tester des choses. Pour illustrer cela, je vous invite à consulté la revue IPOL Journal que j’ai récemment découverte lors des journées Frédoc2013 d’Aussois. Je trouve cela très stimulant ! D’autant que la discussion d’hier soir a jeté les bases de la structure de la revue qui pourrait être éditée par l’association et la question de la place d’articles n’ayant pas une écriture académique a été abordée. Rubriques, cahiers, n° spéciaux, beaucoup de choses sont possibles je pense, et j’y contribuerai avec joie.
Les THATCamps sont des moments assez uniques ou les personnes s’agrègent le temps d’un « week-end » ou plus pour partager leur vision des humanités numériques/digitales. Il y a déjà des comptes-rendus en ligne, dont celui de Camille Bosqué, doctorante à Rennes2 travaillant sur les FabLab, qui a su très bien saisir par le dessin, un moment de l’atelier définissant la constituante de l’association.
Bonjour,
Il y a longtemps que je voulais faire une petite vidéo d’écran pour montrer comment « embarquer » – c’est le terme consacré – une photographique numérique déposée dans MédiHAL (réalisée par le centre pour la communication scientifique directe) dans une plateforme d’édition électronique telle que hypotheses.org (réalisée par le centre pour l’édition électronique ouverte). Comme, je suis en congés, j’ai pris le temps de la faire hier soir. Elle inaugure une nouvelle série de billet de ce blog, les « vidéos pédagogiques de pouyllau » qui auront vocation de montrer qu’il est possible d’articuler les plateformes web entre elles afin de proposer des contenus, articles, des données< riches, etc en exploitant les possibilités de partage, API, etc. de ces dernières. Cela dit, je signale d'ailleurs qu'il existe un carnet de recherche sur hypotheses.org qui regroupe des conseils d'utilisation, annonces, autour de la plateforme hypotheses : c'est la maison des carnets. Vous y trouverez une vidéo similaire présentant comment « embarquer » des données venant d’Archive.org, Youtube, etc. MédiHAL, archive ouverte publique, archivée au CINES, présente l’intérêt d’être une plateforme ouverte, proposant plusieurs services de valorisation des fonds photographiques qui y sont déposés : les collections de MédiHAL en particulier.
A lire les comptes-rendus des différentes journées sur les humanités numériques qui ont lieu ce printemps, je me demande s’il n’y a pas un lien de plus en plus fort entre humanités numériques et le monde industriel. En effet, le monde de l’industrie créé des outils mais surtout y réfléchit et les fait évoluer à la recherche d’une meilleure précision, d’une meilleure performance. Le besoin d’introduire, lors du déroulement d’un projet se réclamant des humanités numériques, une réflexion épistémologique, voir sociologique, me fait penser que le temps du « c’est de la technique, de l’informatique donc ce n’est pas de la science » est peut-être entrain de passer derrière nous. Les humanités numériques se peuplent de séminaires épistémologiques ouvrant une nouvelle dimension pour ce mouvement. Paradoxalement, une partie d’entre elles pourrait être condamnées « à disparaitre ». Le volet le plus technique, l’adaptation d’outils à un besoin par exemple, pourrait être transformé par la mutation permanente des méthodes et par l’appropriation/démocratisation de savoir-faire dit « technique » par un grand nombre d’acteurs. Un peu comme pour les ouvriers de chez Renault quand l’automation introduite par Pierre Bézier s’est développée. Évolution naturelle ? Les humanités numériques sont elles simplement les sciences humaines et sociales dans un monde numérique ? Donc, nous sommes au moment ou la recherche en SHS se fait avec des outils numériques dans un monde « devenu » lui aussi numérique. Le monde industriel – je pense à l’aviation par exemple – créée ses outils, ses machines-outils, réfléchit sur ces outils, améliore sans cesse ses chaines de production : c’est à dire les liaisons entre les briques-outils qui les composent. Il reste des savoir-faire à relier en particulier sur l’édition-documentation-archivage, il reste des pratiques à changer : séparation données/outils de traitement (dans une perspective d’archivage des corpus de données) ou encore il reste à ré-introduire l’explicitation systématique des méthodes, choix effectués et ne plus parler vaguement par exemple autour de la notion de métadonnées. Ce « parallèle » que je me permet de faire entre humanités numériques et industrie est surtout là pour affirmer qu’elles sont avant tout l’utilisation de techniques dans un processus de recherche, en fait de l’ingénierie (documentaire en particulier), comme Got me le rappelait il y a quelques temps. Ainsi, il ne faudrait pas que soit exclu du mouvement des humanités numériques, des acteurs qui n’incorporeraient pas dans leurs projets cette dimension épistémologique.
Comment exprimer des métadonnées d’une page web très simplement en utilisant la syntaxe RDFa ? Prenons exemple un billet de blog « propulsé » par WordPress. S’il existe des plugins pour cela, l’obsolescence de ces derniers peut rendre difficile leur maintien dans le temps. Autre solution, implémenter RDFa dans le code HTML du thème WordPress que l’on aura choisi. Pour ce que cela soit facile et « gérable » dans le temps, le plus simple et d’utiliser l’entête HTML <head> afin d’y placer des balises <meta> qui contiendront les métadonnées. Exprimer des métadonnées selon le modèle RDF via la syntaxe RDFa permet à des machines (principalement des moteurs de recherche) de mieux traiter l’information car elle devient plus explicite : pour une machine, une chaine de caractère peut être un titre ou un résumé, si vous ne lui dites pas que c’est un titre ou que c’est un résumé elle ne le devinera pas. A minima, il est donc possible d’utiliser les balises <meta> pour définir une structure RDF offrant la possibilité de structurer les métadonnées minimales par exemple avec le vocabulaire documentaire Dublin Core Element Set (plus connu en France sous appellation « Dublin Core simple »).
Comment faire ?
En premier, il faut indiquer dans le DOCTYPE de la page web, qu’elle va contenir des informations qui vont utiliser le modèle RDF, ainsi, le DOCTYPE sera :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN" "http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
Dans la balise <html>, nous allons indiquer les adresses des vocabulaires documentaires – par l’intermédiaire de namespace XML – qui vont nous servir à typer les informations, dans notre exemple, nous allons utiliser le Dublin Core simple et le Dublin Core Terms (DC Terms) :
Ici, foaf nous servirait à encoder des informations relatives à une personne ou un objet décrit par les métadonnées, cc nous permettrait de signaler quelle licence creative commons s’appliquerait à ce contenu. Après avoir déclaré des les vocabulaires documentaires que nous allons utiliser, nous allons ajouter la structure RDFa au travers de balises <meta> dans l’entête <head> de la page HTML.
Dans un premier temps, à l’aide d’une balise <link>, nous allons définir l’objet numérique auquel les informations encodées en RDF seront rattachées :
Cette balise définie donc un « conteneur » pour les informations que nous allons indiquer à l’aide des balises <meta>. Ce conteneur est identifié par une URI qui se trouve être là une URL, c’est à dire l’adresse de la page dans le web.
Maintenant, nous enchainons les balises <meta> qui définissent donc un ensemble de métadonnées, c’est à dire dans notre cas, des informations descriptives de la page web :
Il s’agit là d’un exemple minimal : un billet de blog utilisant le Dublin Core simple et peu descriptif sur le plan documentaire. Suivant la nature du contenu de la page web, il sera bien sur possible d’être plus précis, plus fin et plus complet dans les informations encodées. Le DC Terms permettra avec :
<meta property="dcterms:bibliographicCitation" content="Mettre ici une référence bibliographique" />
de proposer une forme pour une référence bibliographique dans le cas d’une page web décrivant un ouvrage par exemple. Il serait possible de passer l’ensemble du texte d’une page web à l’aide du vocabulaire SIOC en utilisant la propriété sioc:content. Il est possible également de relier des pages web entre elles (pour définir un corpus d’auteurs par exemple) en utilisant dans le vocabulaire DC Terms la propriété dcterms:isPartOf.
Il s’agit là d’un court billet présentant une façon très simple d’implémenter des métadonnées descriptives utilisant le formalisme RDF via une implémentation directe dans le code HTML, ce que l’on appelle le RDFa (« a » pour « in attributes« ). Cette implémentation, même minimale, permet d’être indexé par Isidore par exemple et d’indiquer des informations qui seront utilisées pour une meilleure indexation des données et qui pourront être ré-exposées dans la base de données RDF de ce dernier. La plateforme hypotheses.org (éditée par Open Edition) utilise cette implémentation d’RDFa. Pour cela, il faut simplement construire un sitemap (carte des liens du site web) au format xml pointant toutes les adresses URL des pages contenant du RDFa et que l’on souhaite voir indexer par Isidore.
ChronoSIDORE n’est pas le nom d’une nouvelle espèce de dinosaures, c’est le nom d’une application web qui utilise les ressources d’Isidore. ChronoSIDORE est donc un petit « mashup » que j’ai programmé pendant mes congés d’été. L’idée est double, poursuivre l’exploration concrète des possibilités d’un outil comme Isidore et donner des idées à d’autres personnes, en particulier dans le monde des bibliothèques et de la documentation, pour développer d’autres mashups s’appuyant soit sur l’API d’Isidore soit sur son SPARQL endpoint.
Que propose-t-il ?
ChronoSIDORE, accessible sur www.stephanepouyllau.org/labs/isidore/chronosidore, propose une autre façon de « voir » les ressources d’Isidore ; différente des vues traditionnelles en « pages de résultats » comme cela est le cas dans les bases de données bibliographiques ou catalogues. Ce mashup propose une vision des ressources en « tableau de bord » : il s’agit de projeter sur une frise chronologique un ensemble de ressources issues d’une ou de plusieurs requêtes SPARQL. Ainsi, une vision plus globale est proposée permettant une représentation différente de la répartition des ressources : dans notre cas, une mise en lumière de l’évolution disciplinaire des ressources fondée sur la catégorisation automatique effectuée par Isidore. ChronoSIDORE offre la possibilité de « voir » l’évolution chronologique des tendances disciplinaires pour un ensemble fini de ressources documentaires définit dans Isidore ou « source » : il peut s’agir des publications d’un laboratoire (à la condition qu’il possède une collection dans HALSHS), des articles d’une revue, des notices d’une base de données, des billets d’un carnet de recherche (voir la liste des sources dans l’annuaire d’Isidore). ChronoSIDORE propose deux types de requêtes SPARQL : l’une est orientée « sources » la seconde est orienté « auteurs » (permettant de projeter sur la frise les ressources d’un auteur). ChronoIsidore est un exemple de mashup possible, bien d’autres mashup sont possibles (autour des langues, des types de documents…).
Comment fonctionne-t-il ?
N’étant pas un développeur professionnel, j’ai fais avec mes connaissances en PHP, Xpath, SPARQL et Javascript pour développer. J’en profite pour remercier ici mes collègues Laurent Capelli, Shadia Kilouchi et Jean-Luc Minel qui m’ont aidé, en particulier sur SPARQL. Ainsi, je pense qu’une équipe de développeurs professionnels ferait beaucoup mieux, mais j’ai pensé aussi qu’il serait bien de montrer que l’ancien étudiant en histoire et archéologie du Moyen Age que je suis est capable d’exploiter avec un peu de PHP, les gisements de données enrichies proposés par Isidore, en espérant que cela donnera des idées à d’autres. J’en profite pour ré-affirmer ici le rôle et l’importance des ingénieurs en digital humanities dont les métiers sont multiples et qui interviennent à différents niveaux de technicité : Il faut des très grands spécialistes, érudits mais aussi des intermédiaires qui vont chercher la compétence à l’extérieur et l’adapte aux besoins SHS . On fait souvent le reproche aux ingénieurs du CNRS, surtout en digital humanities, de ré-inventer l’eau chaude, mais je pense qu’ils développent des outils, des méthodes qui sont adaptés à des publics présentant une multitude de rapports au numérique et différents niveaux d’appropriation et c’est très important. Il faut parfois avoir un outil imparfait, ou un démonstrateur fonctionnel pour offrir un service qui permettra à certains de profiter d’outils communs, fondés sur des standards ouverts et bien documentés et de « sauter le pas », ensuite on peut toujours améliorer les fonctionnalités. Je préfère cela à deux extrêmes : passer cinq ans à faire un outil qui ne fonctionnera jamais et qui sera dépassé avant de sortir (car nous n’avons que trop rarement les moyens de faire vite et bien) et dire qu’au prétexte que cela existe en ligne, il ne faut rien, s’en contenter, faire avec, et ne rien tenter car on n’égalera jamais les autres. Il s’agit parfois de faire juste « un pas de plus » pour ouvrir des données aux autres et savoir que ce « pas » est maitrisé, accompagné par des collègues du monde académique peut être plus sécurisant que de plonger de suite dans jungle des outils en lignes et des « consultants » (même si, comme je l’ai dit, cela peut être nécessaire). J’aime bien l’idée que ChronoSIDORE donnera peut-être des idées à d’autres, nous en reparlerons au THATCamp Paris 2012 en septembre.
ChonoSIDORE réalise en fait plusieurs tâches :
Il interroge le triple store RDF d’Isidore : il s’agit d’une base de données RDF qui contient l’ensemble des informations d’Isidore formalisées en RDF et proposées selon les principes du linked data.
Il utilise pour cela le langage normalisé et international SPARQL (W3C) qui permet d’interroger les triplets RDF.
Il assemble les informations reçues du triple store sous la forme d’un flux de réponse Xml lisible avec l’application timeline créé dans le cadre du projet Simile du MIT (plutôt que refaire un système propre, j’ai préféré utiliser cet outil, même si je le trouve quelque peu rigide, il existe aussi d’autres systèmes : par exemple Timeline JS mais quelque peu différent).
Quelques limites
Il s’agit d’une version bêta, en fait un démonstrateur, donc il présente des limites. Deux sont à signaler :
Isidore catégorise automatiquement via un corpus de référence (HALSHS) et à l’aide de signatures sémantiques : cela peut donc générer des erreurs de catégorisation. Pour aller plus loin, voir les principes de catégorisation dans Isidore avec la vidéo de présentation des systèmes d’Isidore par Fabrice Lacroix, président d’Antidot, lors de l’université d’hiver du TGE Adonis à Valpré en décembre 2010 (ouverture d’Isidore).
Isidore ne catégorise pas toute les ressources qu’il moissonne : cela dépend de la richesse sémantique des métadonnées : plus les métadonnées moissonnée seront riches (description, résumé, mots-clés) plus la catégorisation proposée par Isidore sera pertinente et donc utilisable dans ChronoSIDORE. Donc toutes les ressources ne « montent » pas dans la frise chronologie.
Je vous invite donc à utiliser ChronoSIDORE, à le tester, à le faire « craquer » et si vous le souhaitez vous pouvez laisser un commentaire, des idées, des critiques…
Je signale le très bon billet sur l’interopérabilité de Marie-Anne Chabin dans son blog (merci d’ailleurs à Silvère Mercier pour le signalement). Je me suis permis un petit et court commentaire à ce billet car il fait écho en partie aux limites de l’interopérabilité quand elle devient plus une mode qu’un besoin réel. C’est particulièrement vrai dans le monde de l’interopérabilité des métadonnées documentaires ou le protocole OAI-PMH est largement utilisé (ce qui est bien) mais parfois mal maitrisé : Il est courant de tomber sur des entrepôts OAI-PMH qui tentent d’échanger des métadonnées qui, non-normalisées par exemple, ne trouveront pas d’utilisateurs « en face » pour les exploiter réellement.
En écho complémentaire, je signale la journée d’étude « De l’OAI au web de données : Bibliothèques et publications sur Internet » le 12 octobre 2012 qui se propose d’explorer le lien entre interopérabilité et utilisation du web comme lieu de publication même des informations structurées. Pour finir, je me permet de vous encourager de regarder et d’écouter de temps en temps l’intervention d’Emmanuelle Bermes sur le web de données qui éclaire toutes ces notions de façon magistrale.
Depuis quelques semaines, j’ai pris la direction d’une unité mixte de service qui anime la très grande infrastructure de recherche Corpus-IR. Après Adonis et tout en poursuivant un peu l’animation d’Isidore, je reviens avec plaisir dans les corpus de données en SHS. Cela dit, l’avenir d’un projet tel qu’Isidore est très directement lié aux corpus et bases de données qui pourraient être indexés et annotés par Isidore. Les consortiums de Corpus-IR sont déjà au travail et proposeront des corpus de données prochainement. J’espère qu’ils seront structurés avec du RDF et voir même, pour les corpus diffusés sur le web, avec du RDFa.
Ayant donc un peu moins de temps pour écrire dans ce blog, je profite tout de même de quelques minutes pour vous inviter à explorer les possibilités du SPARQL endpoint d’Isidore en lançant ici une petite série de billets. Pour ouvrir la série, une requête permettant de lister les métadonnées des photos et images de MédiHAL géolocalisées sur territoire (je prends ici quelques photos de Djibouti) appartenant au référentiel géographique utilisé dans Isidore, Geonames.org :
En posant cette requête SPARQL dans l’interface d’interrogation SPARQL d’Isidore, il est possible de récupérer les métadonnées, en fait les informations contenues dans les métadonnées, sous la forme de triplets RDF. Ces triplets RDF, base du web de données, peuvent donc être redondant si l’information fait appel aux même étiquettes d’un même vocabulaire (cf ex. ci-dessous). Le résultat de la requête est présenté dans différents formats (RDF/XML ; HTML ; json…).
A partir de là, de nombreuses petites applications web sont possibles, elle sont souvent nommées « mashup » car elles marient, grâce au liant que permet l’utilisation d’URIs à base d’http, plusieurs informations présentes dans le web de données.
Bon, je m’arrête là pour ce premier petit billet qui n’a pas d’autre vocation que de présenter des exemples de requêtes SPARQL sur des données SHS afin de mettre un peu l’eau à la bouche aux développeurs web du domaine qui pourraient ainsi avoir des idées de mashup pour leurs productions. La prochaine fois, je présenterai comment est formé de la requête.
Dans un billet récent, Alexandre Moatti, faisait quelques remarques sur la bibliothèque numérique de l’Institut. Dans son texte, il fait référence à ICEberg, un logiciel que j’ai créé en 2002-2003 afin de proposer un outil de mise en ligne de corpus numériques. ICEberg a évolué avec le temps et il a été ré-écrit 3 fois depuis 2002.
C’est normal, les outils en ligne (les applications web) sont très vite obsolètes : les briques permettant de les construire (PHP, Python, Jquery, etc.) évoluent en permanence et contraignent donc les développeurs et webmasters à faire régulièrement des nouvelles moutures de leurs programmes. Depuis la généralisation des systèmes de gestion de contenu (CMS) de 2eme et 3eme génération se sont ajoutées aux couches basses (PHP, MySQL, version d’Apache ou d’IIS) une kyrielle de modules qui ont la fâcheuse tendance à ne plus être compatibles avec le noyau du CMS après parfois quelques semaines seulement.
Dans certains cas, des modules importants ont été incorporés dans le noyau ; mais pour beaucoup de fonctionnalités, le recours à de nouveaux modules répondant à des besoins toujours nouveaux (OAI-PMH, « zotero inside », galeries d’images, etc.) est devenu un automatisme pour les webmasters : « oh, il doit y avoir un module qui fait cela ». Dans certains cas, le nombre de modules est déjà très important alors que l’outil lui-même vient tout juste de passer en version 1.0. Si la qualité des modules et leur nombre peuvent être des signes de la vitalité d’un projet, il faut cependant faire attention à bien anticiper la maintenance sur le moyen terme (je dis bien moyen terme, tant le long terme n’est pas compatible avec l’obsolescence des outils web je pense).
Confier de façon exclusive à un module en version béta par exemple, l’interopérabilité OAI-PMH des métadonnées de son corpus, veut dire que l’on prend un risque à moyen terme, si le module n’est plus maintenu pour x. raison(s). Je ne dis pas qu’il ne faut pas l’utiliser, mais il faut avoir conscience du risque et donc avoir des solutions de remplacement. Il faut faire de la veille. Pour illustrer cela, l’animation et la veille faite par l’équipe d’Open Edition sur les modules de la plate-forme hypotheses.org est exemplaire : les modules demandés par les blogueurs sont testés, évalués puis le cas échéants proposés dans les blogs. Cependant, à moyen terme, cela n’enlève pas l’obsolescence technique des modules, mais permet d’anticiper l’évolution. La veille est donc l’indispensable compagnon des administrateurs de sites et bibliothèques.
Mais au delà, je me pose la question de la limite des CMS dans le contexte de la recherche par projets (c’est à dire avec des ruptures de charges). Les bibliothèques scientifiques, universitaires et de recherche devraient développer des structures de conservation des corpus numériques incluant, outre l’archivage pérenne des données, la conservation de la structuration intellectuelle du corpus (structuration des bases de données, manuels de saisie, publications associé aux données, schéma de métadonnées, etc.). Encore une fois, c’est par l’association des métiers et le passage de responsabilité entre les acteurs du domaine que la pérennité deviendra réelle.
Le Centre André Chastel (Université de Paris-Sorbonne, Paris IV, CNRS, Ministère de la Culture et de la Communication) propose une édition électronique de la correspondance d’Eugène Delacroix (1798-1863). Accessible sur le site www.correspondance-delacroix.fr, le site est très clair et fonctionnel : il y a un moteur de recherche, un index des noms de personnes, des liens offrent la possibilité de naviguer dans le corpus. La visualisation des lettres est aussi très intéressante : fac-similés (flash, mais visualisation de l’image jpg sous ipad par exemple), transcriptions, notices biographiques, annotations, etc. Le projet semble très bien mené et rentre dans le mouvement des éditions électroniques de correspondances (littéraires, scientifiques, etc.). Ce projet a été financé par l’Agence nationale de la recherche en 2006 (appel Corpus).
On peut cependant regretter d’avoir à faire à un site « clos ».
Je m’explique : les éditeurs ont conçu un site très riche et bien pensé, mais ils n’ont pas mis en place de politique de flux de diffusion (RSS, Atom) permettant par exemple de suivre, depuis un outil de veille, les mises à jour des annotations afin de suivre les débats des spécialistes. C’est dommage car le site se veut vivant : « …grâce à la mise en ligne, [les transcriptions et annotations] seront toujours susceptibles de modifications et d’ajouts » est-il précisé dans la présentation du projet. Quel est le système de transcriptions qui a été utilisé ? Text Encoding Initiative ? Nous ne le savons pas : c’est dommage car cela aurait marqué un peu la préoccupation des éditeurs en matière d’archivage des transcriptions (même si TEI n’est pas parfait, c’est déjà au moins du XML). Autre manque : alors qu’un effort a été visiblement fait pour rendre citable les url des lettres (indépendance des liens vis à vis du système de publication), il n’est pas fait état d’un hypothétique entrepôt OAI-PMH permettant de moissonner les métadonnées des lettres de Delacroix afin de les diffuser dans les portail tel OAIster, Gallica ou ISIDORE, comme c’est le cas pour les correspondances d’André-Marie Ampère ou encore Buffon. Est-ce une volonté des éditeurs ? un oubli par manque d’information (OAI-PMH reste tout de même assez mal connu) ? Je ne sais pas. Mais, je pense qu’il est toujours dommage de ne pas disséminer les contenus d’une édition électronique d’une œuvre scientifique, littéraire ou artistique vers des portails thématiques ou disciplinaires afin de communiquer plus largement les sources de la recherche et de les rapprocher d’autres ressources. Globalement, le corpus est certes utilisable mais est-il réutilisable ? Je l’espère. En tout cas, il me tarde de voir signaler les échanges épistolaires d’Eugène Delacroix dans ISIDORE (qui contient déjà 256 ressources sur ce dernier).
Le portail BASE (Bielefeld Academic Search Engine) est un aggrégateur OAI-PMH moissonnant 1890 entrepôts OAI dans le monde (au 2 juillet 2011) et donnant accès à 28.911.265 notices. Utilisant Solr et le système d’opac VuFind, BASE est accessible via un site web très clair, rapide et fonctionnel. Sans proposer, comme dans ISIDORE, un enrichissement des métadonnées à l’aide de référentiels, ni l’indexation du texte intégral des données jointes aux notices OAI, BASE est un outil très performant qui fait partie des fournisseurs de services. « Fournisseurs de services »… cette expression, un peu obscure je trouve, désigne le plus souvent les portails documentaires moissonnant des métadonnées selon le protocole OAI-PMH. Après OAIster (aujourd’hui dissout dans l’offre d’OCLC), Scientificcommons.org, BASE a ses adeptes. En tous cas, ce projet conforte certains choix que nous avons fait dans ISIDORE : la mise en place d’un annuaire des entrepôts moissonnés (« A data resources inventory provides transparency in the searches« , voir dans « About BASE« ) ou encore la notion de web profond ou invisible « Discloses web resources of the « Deep Web », which are ignored by commercial search engines or get lost in the vast quantity of hits.« . Bien sur, la notion de facettes, mais calculées uniquement sur les contenus des métadonnées moissonnées : « Refine your search result » options (authors, subject headings, year, resources and language).
Limité à OAI-PMH, et donc à des métadonnées proposées sous la forme d’atomes sans relief, ce type de portail, comme ISIDORE d’ailleurs, devra évoluer car il est toujours un peu frustrant de ne pas naviguer dans des données en « relief ». ISIDORE, avec son SPARQL end point RDF contenant plus de 40 millions de triplets RDF, va déjà un peu plus loin, mais il nous faut imaginer des nouveaux systèmes de navigation et de signalement pour ces informations structurées en RDF.
Aujourd’hui, j’ai le plaisir de participer au lancement officiel d’ISIDORE, la plateforme de recherche dans les données numériques de la recherche en sciences humaines et sociales. Réalisée par le très grand équipement Adonis du CNRS, ISIDORE est une production collective qui a associé depuis plus de deux ans des acteurs publics et des acteurs privés au sein d’un marché de réalisation. Public tout d’abord : ISIDORE est un projet qui est la matérialisation concrète du projet fondateur du TGE Adonis : donner accès à de l’information, ouvrir des données, rendre visible la production des chercheurs et les données qu’ils utilisent pour travailler. Au sein du TGE Adonis un grand nombre de collègues ont travaillé pour ce projet, ils ont défini le projet, l’ont argumenté, le réalise aujourd’hui : c’est un travail d’équipe, long, complexe, parfois périlleux car il faut faire acte de pédagogie et de pragmatisme technique. Je vous invite à consulter ISIDORE, à le critiquer pour le faire évoluer car un outil tel que celui-ci doit évoluer en permanence. Je veux simplement souligner le très grand professionnalisme des collègues, partenaires industriels, qui ont partagé avec moi l’ensemble de la conception/réalisation de ce projet depuis mon arrivée au TGE en avril 2009 : Yannick, Benoit, Ariane, Nadine, Jean-Luc, puis Richard et Jean-Luc, Sophie, Shadia, L’équipe de la maitrise d’œuvre avec un immense respect pour Laurent tout d’abord, puis Daniel, Loic, Philippe, enfin tous les collègues du CNRS qui ont participé, soutenu, critiqué, aidé. Coté prestataires, je souligne le très grand professionnalisme des équipes ont travaillé avec nous et bien sur merci à Bruno, Jean-Louis, Fabrice et Gautier sans qui ISIDORE ne serait pas ISIDORE. Merci à tous !!







 Résultat : on surfe à la vitesse ultra rapide de… 19200 bit/s (19 kbit/s) ! Cela est suffisant pour faire du… FTP ou du Telnet (haaaa
Résultat : on surfe à la vitesse ultra rapide de… 19200 bit/s (19 kbit/s) ! Cela est suffisant pour faire du… FTP ou du Telnet (haaaa